R의 산술연산자

- +(더하기), -(빼기), *(곱하기), /(나누기 - 실수, 정수)
- %/% : 정수 나눗셈을 할 때 몫만 출력
- %%(나머지) : 나머지 값 계산
- ^ 또는 ** : 제곱
R의 변수

- 값을 저장하기 위한 메모리 공간을 확보하여 변수명(식별자)을 붙인 것
- 형식 : 변수명<-값
- 변수명의 첫 글자는 반드시 문자로 시작
- 변수명으로 예약어 사용 불가, 대소문자 구분
- C언어처럼 문자열과 문자를 구분하지 않는다.
- 동일한 데이터 형식을 하나의 변수에 묶어둔다. --> 벡터 , c함수 사용



R의 자료형(data type)

<스칼라 타입>
정수 : 1, 2, 3, 4, ...
실수 : 5.8, 7.7777, 123.45, ...
문자열 : "안녕", "반가워", ...
진릿값 : TRUE, FALSE
날짜/시간 : "2020-02-22", ...
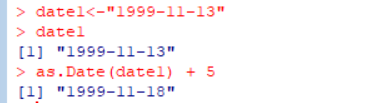
Sys.Date() : 시스템 날짜를 표시하기 위한 함수
as.Date(변수명) : 문자열 데이터 값을 날짜형으로 변환해준다.

<NA 데이터 타입>
: Not Available --> 결측값(데이터 값이 없음)
- is.na() 함수 : 변수의 NA 값이 있는지 확인
- NA값이 들어있으면 sum()함수 계산 불가능
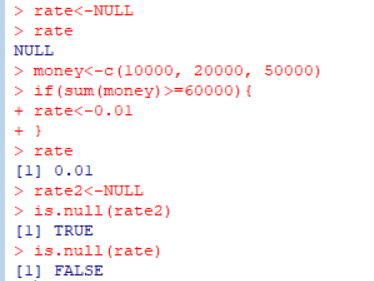
<NULL 데이터 타입>
: 데이터 값이 정해지지 않은 상태(undefined)
- is.null(변수명) : 현재 변수가 null인지 확인
<Factor 타입>
- 범주형 데이터(categroy)
1. 명목형 데이터(순서X) : 종교(천주교, 기독교, 불교), 의결(찬성, 반대) ...
2. 순서형 데이터(순서O) : 크기(대, 중, 소) ...
- vector형식의 한 형태
- 중복되는 값들이 존재할 때 중복되는 값들 중 1개씩만 모아서 목록을 만들어준다.
- factor의 ordered의 기본값 : FALSE(명목형 데이터)
factor(x, levels, ordered)
#x : factor로 표현하고자 하는 값
#levels : factor 레벨의 목록을 보여줌
#ordered : TRUE(순서형 데이터), FALSE(명목형 데이터)
table(x) #level에 따라 몇개의 값이 존재하는지 count값 출력
unclass(x) #목록의 단순 상수값만을 출력하고 해당 상수가 의미하는 데이터 값 표시

<Vector 타입>
: 여러 변수들을 하나의 이름으로 묶은 집합
- 같은 유형의 데이터를 여러 개 변수로 보관해야 할 경우 벡터를 사용
- 벡터의 항목 변경 가능
- 인덱스는 C언어와 달리 1부터 시작한다.
- 벡터의 각 항목에 이름을 부여하여 이름으로도 접근이 가능
- c() 함수를 이용해서 벡터 생성
coffee<-c(3000, 4500, 4500, 5500)
x<-1:5 #c() 함수 사용 안하고 :로 연속되는 숫자를 담는 vector 만들기- 벡터 항목의 요소들은 한가지 데이터 타입이어야 하고 그렇지 않다면 강제 형변환을 일으킨다.
(ex. 정수형과 실수형이 같이 들어가게 되면 실수형으로 강제 형변환
문자와 숫자가 같이 들어가게 되면 문자로 강제 형변환)

- 벡터 항목에 이름 설정하기
names() 함수를 이용하여 이름 설정
names() 반환값은 지정한 이름값을 문자열 벡터에 할당
names(coffee)<-c("아메리카노", 에스프레소", "카라멜마끼아또", "콜드브루")
- 벡터 접근
vector[n] #n번째 항목에 접근
vector["이름"] #이름에 해당하는 항목 접근
vector[s:e] #s번째 항목부터 e번째 항목에 접근
vector[-n] #n번째 항목만 제외하고 나머지 항목 접근
- 벡터 연산
coffee["에스프레소"]+500 # 벡터의 특정 항목에 접근하여 계산
#위의 코드를 입력하면 계산값이 출력되고 vector의 결과값이 바뀌는 것은 아님
coffee+1000 #벡터 전체에 대한 연산작업을 일괄적으로 실행
- 벡터 집합연산
벡터를 하나의 집합으로 간주하고 집합 간의 교집합, 합집합, 일치 여부 등을 연산
identical(x,y) # 두 집합의 항목이 일치하면 TRUE, 일치하지 않으면 FALSE
union(x,y) # 두 집합의 항목을 합집합 계산
intersect(x,y) # 두 집합의 항목을 교집합 계산
setdiff(x,y) # x의 차집합 계산
setequal(x,y) # 두 집합의 구성값이 동일하면 TRUE, 동일하지 않으면 FALSE
- 벡터에 연속적 데이터 할당
seq(시작값, 끝값,증가값) #연속적 데이터를 할당
rep(반복할 벡터항목, times(또는 each)) #반복적 항목으로 이루어진 벡터생성
#times – 반복할 벡터항목 전체를 몇번 반복할 것인지 횟수를 기술
#each – 반복할 벡터항목 각각을 몇번 반복할 것인지 횟수를 기술
- 벡터 길이 구하기
length(벡터) #해당 벡터 길이 계산
NROW(벡터) #벡터, 행렬의 행, 데이터프레임의 행 수를 계산하여 보여줌
- 비어있는 벡터 만들기
a<-vector(mode="numeric", length=10)
#실행 결과 0 0 0 0 0 0 0 0 0 0'study > 빅데이터 분석' 카테고리의 다른 글
| [R프로그래밍] #6. 외부파일 읽어오기 (0) | 2021.06.30 |
|---|---|
| [R프로그래밍] #5. 조건제어문, 함수 (0) | 2021.06.29 |
| [R프로그래밍] #4. 자료형-2 (list, matrix), 데이터프레임 (0) | 2021.06.21 |
| [R프로그래밍] #2. R 패키지 설치 (0) | 2021.06.18 |
| [R프로그래밍] #1. R프로그래밍 정의 및 특징, R 설치, JDK 설치 (0) | 2021.06.18 |



