A computational approach to body mass index prediction from face images
얼굴 이미지로부터 체질량 지수 예측에 대한 계산적 접근법
< 논문 요약>
통계적 방법으로 얼굴 이미지를 통해 BMI를 예측할 수 있다.
0. BMI
BMI : 개인의 키와 몸무게를 기준으로 한 체지방의 척도
단위에 따라 계산 식이 나눠진다.
BMI를 기준으로 저체중, 정상, 과체중, 비만으로 나눠진다.


1. 데이터 : MORPH-II database
MORPH-II는 약 55000개의 얼굴 이미지.
이 데이터에서 연령, 성별, 민족 분포 등의 불균형때문에
약 96%에 해당되는 White and Black faces image만을 연구에서 사용한다.
또한 성별과 연령대 분포를 고려하여 얼굴 이미지의 일부를 선택하여 2가지 세트로 나누어서 사용한다.
세트 1 : 7273개 (ID : 4591개)
세트 2 : 7323개 (ID : 4590개)

데이터의 target 값인 BMI의 분포는 주로 15-35 사이의 범위에 있다.

2. Face image로 BMI를 예측하는 과정

2.1. Face detection, alignment, and fitting
1. 얼굴과 두 눈 감지
2. 검출된 각 면이 검출된 눈 좌표를 기준으로 정규화
: 기본적으로 모든 얼굴 이미지를 공통 눈 좌표로 정렬할 수 있도록 얼굴의 화전, 변환 및 스케일링 수행
3. ASM(the active shape model)
: 얼굴 이미지의 여러 기준점을 탐지하는 역할
얼굴 구성요소의 위치(눈, 코, 입술, 얼굴 윤곽 등)에 주성분 분석(PCA) 적용 후
포즈, 조명, 표정 변화등을 고려하여(?) 다양한 수동 라벨 이미지로부터 연결된 포인트 분포로 ASM 제시

옆의 사진 : ASM 적용 예시 (출처 : 논문)
76개의 점이 탐지됨
ASM 모델을 다양한 크기의 얼굴 및 머리 회전이 포함된 원본이미지 대신 정규화된 얼굴 이미지에 적용
: 기준점 검출 보다 강력하고 정확하게 해준다.
2.2 Facial feature
7가지 얼굴 특징을 자동 감지 및 추정된다. 앞에서 구한 ASM의 점들 중 20개의 점(사진에서 P점들)과 ASM 방법에 의해 검출된 기준점을 기준으로 4개의 점(N)의 위치를 추정하여 총 24개의 점을 사용하여 7가지 얼굴 특징을 계산한다.
--> 광대뼈 대 턱 너비(CJWR), 너비 대 상부 얼굴 높이 비율(WHR), 둘레 대 면적 비율(PAR), 눈 크기(ES), 얼굴 대 얼굴 높이 비율(LF/FH), 얼굴 너비 대 얼굴 높이 비율(FW/LFH), 눈썹 높이 평균(MEH)

2.3 Normalization

μ is the mean value and σ is the standard deviation, computed from the training data along each feature dimension.
BMI를 더 잘 예측하기 위해 특징 정규화가 중요하다는 것을 발견
2.4 Statistical learning (통계적 학습)
(3개의 모델을 각각 사용한 것으로 생각됨)
1. Support vector regression (SVR)

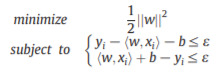
2. Least squares regression

3. Gaussian process regression


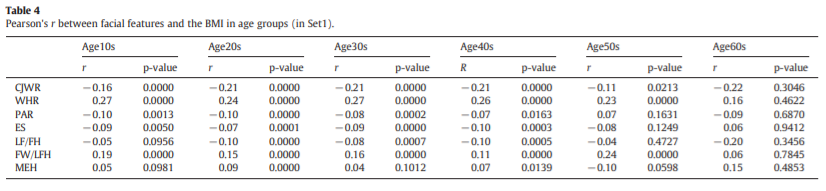
3. facial feature과 BMI의 상관관계
Pearson's correlation 이용
: 두 변수 집합의 상관관계를 측정하는 데 사용됨

r은 -1 <= r <= 1
r < 0 이면 X와 Y 사이 음의 상관관계
r > 0 이면 X와 Y 사이 양의 상관관계
r = 0 이면 상관관계 X
-1과 1에 가까울수록 강한 상관관계
위의 Pearson's 상관계수는 관측된 표본으로부터 계산된다.
표본 수가 많다고 하더라도 전체 모집단에서 측정한 상관관계와 같지 않다.
모집단으로 확장하기 위해 통계량을 사용하여 가설 검정을 수행한다.
p-value는 특정 가설이 참인 방법을 설명한다.
p-value를 사용하여 계산된 얼굴 특징이 BMI 사이의 유의한 상관관계가 존재하는지 여부를 나타낸다.
p-value가 작을수록 상관관계가 높다고 생각되어진다.
따라서 p-value가 임계값(ex)0.001, 0.01, 0.05)과 같거나 작으면 얼굴 특징과 BMI 사이에 유의한 상관 관계가 있음을 나타낸다.
4. Experiments
p-value<= 0.05일 때 유의한 상관관계로 간주한다.
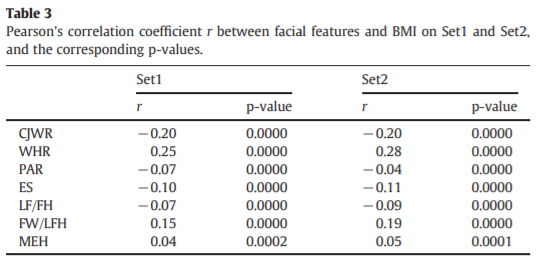
Table3에서 보면 모든 상관관계는 두 데이터 집합의 p-value가 매우 작다는 것을 알 수 있다.
이는 추출된 얼굴 특징이 BMI와 상관관계가 있음을 나타낸다.

위 그래프에서 보듯이 전반적으로 SVR 방법이 GP 및 LSE 방법보다 더 잘 수행된다는 것을 관찰할 수 있다.
성능 예측은 MAE(mean absolute error)를 사용한다.

위 그래프는 저채중, 정상, 과체중, 비만 등 다양한 BMI 범주에 속하는 SVR, GP, LSE의 MAE를 보여준다.
세가지 방법 모두 정상과 과체중 BMI 범주에서 잘 수행된다는 것을 알수있다.
정상 BMI 범주가 전체 중 55%, 과체중이 30% 정도 포함되어 이 두 범주는 전체 집합의 약 85%를 차지한다.
따라서 더 나은 BMI 성능을 예측하기 위해서는 많은 수의 훈련예제가 필요하다는 것을 암시한다.
SVR은 저체중 및 정상에서 더 나은 반면, GP는 과체중 및 비만에서 더 나아 보인다.
SVR의 오차가 전반적으로 가장 작다.
5. 결론
대형 데이터베이스의 상관계수와 p-value 측정은 계산된 얼굴 특징과 BMI간의 상관관계를 통계적으로 의미 있는 방식으로 보여준다.
'study > 영상처리 & opencv' 카테고리의 다른 글
| [논문 요약] Face-to-BMI: Using Computer Vision toInfer Body Mass Index on Social Media (0) | 2021.03.23 |
|---|---|
| [opencv] 3개의 사진 Panorama(image stitching) (9) | 2021.02.04 |
| [영상처리] 가우시안(Gaussian) 필터 (0) | 2021.02.03 |
| [영상처리] Homogeneous coordinates (0) | 2021.01.28 |
| [영상처리] 2D변환 - Rigid Transformation (0) | 2021.01.27 |



